Compared to vision and audition, the sense of smell is an exceptionally ancient one. And you might be surprised but the ability to detect odorous particles (also known as chemosensation) even predates the development of olfactory organs. Our distant cousin, the lancelet, the marine animal which bridges the gap between invertebrates and vertebrates, even shares some olfactory receptor (OR) genes in common with us [1].
Image of several lancelets, also known as “amphioxus,” which means “sharp at both ends.” Image borrowed from here.
In primates, our vision is a culmination of the work of three different color-sensitive photoreceptors: red, green, and blue. But in order to detect different smells, you must have a huge variety of receptors that can sense the odors’ different chemical signatures. Just imagine how many OR genes your genome has to code for so that you can smell all the things you do: hot apple pie, gasoline, freshly mown grass… As you might imagine, the OR family is the single largest gene superfamily in mammals. Humans have hundreds of olfactory receptor genes, and even more degenerated OR pseudogenes [2]. A highly olfactory-driven animal like the mouse meanwhile has over 1,000 OR genes [3]. Interestingly, because the rise of trichromatic color vision in primates seemed to vaguely coincide with the concomitant loss of functional OR genes, it has been hypothesized that a growing dependence on color vision and a declining dependence on olfaction has loosened constraints on mutation rates longterm in apes and humans such that the loss of a given OR gene is comparatively less detrimental than, say, a similar loss in the mouse [4].
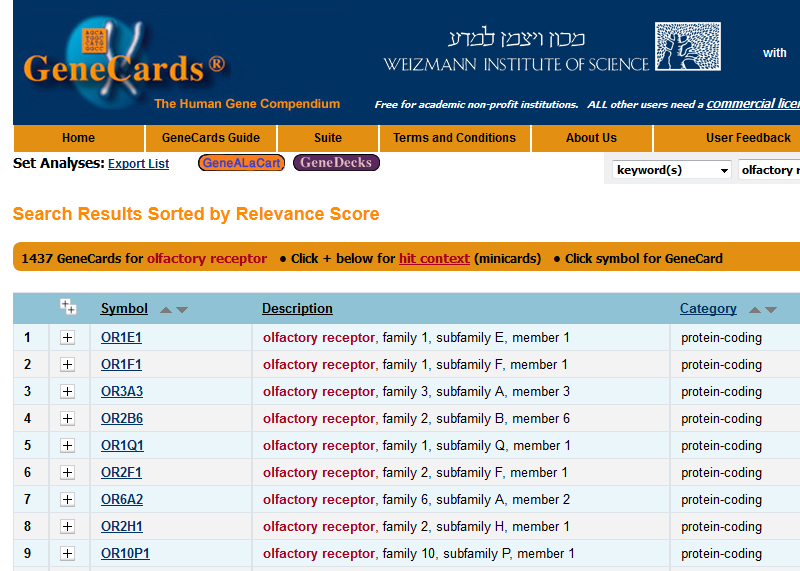
A screenshot taken of the GeneCards listing for “olfactory receptors”, showing the first 9 protein-coding genes of several hundred.
In spite of their huge variety, and for anyone not especially interested in the sense of smell or chemosensation, why are OR genes so interesting? Well I’ll tell you. Most genes within our genome, the protein-coding ones at least, tend to follow certain trends. Smaller genes (the absolute length of the DNA, exons plus introns) tend to be fairly conserved and have low rates of mutation, both within the exons and also within the introns. From my own work I have noticed that well-conserved genes tend to have comparatively few transposable insertions. One can easily see the relation between overall gene size and rate of mutation: the more insertions, the larger and more unstable the gene tends to become over time, which means that really big genes tend to be much more unstable than really small genes on average.
Except OR genes, which are both small and highly unstable. Undoubtedly this tendency towards higher rates of mutation has lead to the incredible variation within their gigantic superfamily. But why are they so unstable? One answer may be this: OR genes usually cluster together in regions that house a large number of retrotransposons [5]. Yep, bookending these genes in their intergenic regions are large numbers of mobile elements which likely promote high rates of mutation and recombination for the ORs. In addition, these genes frequently cluster around subtelomeric regions, areas which tend to exhibit frequent mutation due to their proximity to the highly repetitive unstable telomeric ends of chromosomes [6, 7]. And when I say these guys are “small” I mean they’re really small for a gene. Often under 1,000 base pairs in length. And the prototypical OR sequence houses one 5-prime untranslated region and another protein-coding exon with no intronic content.
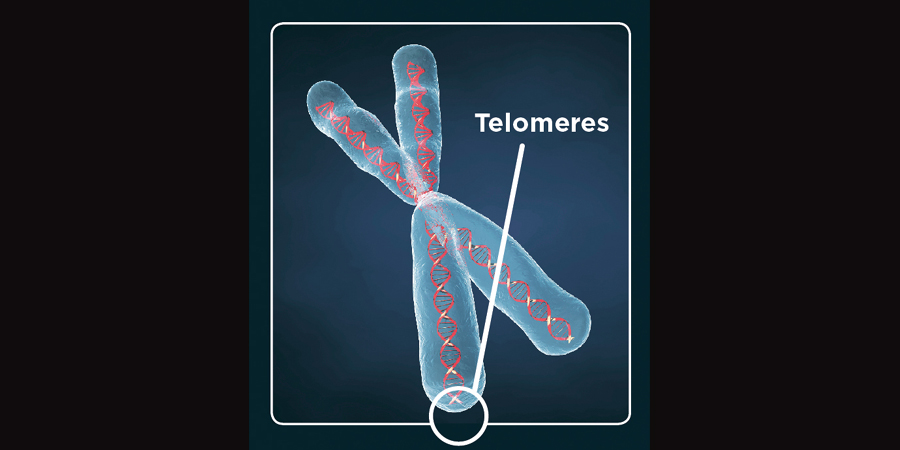
It’s believed that new ORs have been driven by the occurrence of copy number variations (CNV) and subsequent mutation. CNVs are repetitive sequences of DNA in which large sections are either duplicated or duplicated segments are subsequently deleted. As may not be surprising given the mutation-promoting nature of transposable elements, tail ends of CNVs, i.e., the point at which the CNV breaks and duplicates or deletes itself, frequently align with mobile elements, especially the poly-A tails of Alu elements [8]. As suggested, repetitive sequences, even single nucleotide tracts such as “AAAAAAAAAA,” can promote secondary and tertiary conformations such as hairpins, structures which increase the risk for gene instability.
If you recall from my earlier post, “All Roads Once Led to Rome… But Do All Roads Lead to Autism?”, that not only do large genes with considerable intronic content turn up in cancer studies as potential false negatives, but OR genes do as well. Why specifically do large genes and OR genes turn up so frequently in all these different genetics studies? Because they have high rates of mutation, both developmentally and somatically. This means that they have a higher probability of showing up in results compared to more highly conserved genes, even though they may have nothing to do with a given disease phenotype.
It’s hard to remember– or on some level even believe– that if a specific mutation turns up consistently associated with a particular condition that it may have no causal relationship whatsoever. Because we all want to believe it does, since we all want answers to our burning questions. “What causes autism?” “What causes cancer?” “How does schizophrenia develop?” But in those introspective moods in which I occasionally find myself, I ask myself if I want answers, even if they’re wrong. To which I reply a resounding no, and keep looking, keep refining, and keep plodding on.
Even for those who have no such interest in olfaction, the study of olfactory genes may lend a considerable knowledge to understanding how mutations occur in general, why they occur, and what conditions they may or may not lead to.
