Regardless of whatever were the first steps in the origins of life, there is little doubt that the modularity of proto-life’s chemical parts has been a foundational element to Self-replication with Variation. While all component parts of the cell display the telltale marks of modular organization, the genome in particular is rife with it.
Think about it: a sugar connected to a phosphate group on one end and a nitrogenous base on the other, and just by switching out the nitrogenous base for any of the four which typify our genome you have a different module in the quaternary code.
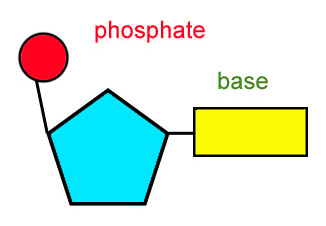
These variations provide for an elegant chemical memory. And yet innate properties in the structural bond formed between any two neighboring nucleotides also provide an additional level of dynamic memory, one which lies above the typical sequence plain of digital primary encoding (A, T, G, C) and instead represents a 3-dimensional relationship between dinucleotides. Each dinucleotide pairing exhibits its own unique rotatory angle around the central axis of the single DNA strand [1]. Add all these up within under a 200bp range and you can begin to understand the anistropic tendencies of that local area, meaning simply that you can see how the local sequence may tend to flex more easily in one direction than in another. This lends towards different binding properties concerning various molecular partners like regulatory RNAs, proteins, and metals. Beyond the length of 200bp the local anisotropies seem to even each other out. If you recall from an earlier post of mine there is the tendency of the larger strand of DNA to behave as a worm-like chain in which it is isotropic or bends equally well in any radial direction.
I have to admit, there was a period in my scientific life when I kind of felt as though DNA was getting way too much professional attention and the remainder of heritable templates (i.e., the rest of the cell) were being largely ignored in the realms of inheritance and evolution. I still think that. But I’ve done a bit of a 360 nowadays in realizing that, while there are numerous modular forms of intergenerational inheritance that ultimately lend towards phenotype, the genome provides a substantial amount of heritable complexity.
While one can argue that there are numerous chemical templates within and outside the cell which ultimately predispose its phenotype, the DNA is both relatively reliable and extraordinarily detailed. There are those scientists who argue that a reductive form of the Citric Acid Cycle is a likely candidate for the first element of “life”, providing a replicative molecular template [2]. But its complexity– though impressive on a metabolic level– is incomparable to the genomic template. The length of the genome is just too huge a database for any other template alone to compare.
So while other metabolic processes may or may not have been the start of “life” and their complexities have only grown from there, the vast amounts of data which can be stored in the genome, by the very nature of its mirrored-form of self-replication, are staggeringly huge. Interestingly, there is some promising evidence from Chen et al. (2004) which suggests that more rapid genomic growth (i.e., replication) may promote cell growth through expansion of the vesicular compartment. That means that cells which replicate their genome more successfully may, even in the short term, experience distinct advantages in cellular size which may subsequently feed back into their capacity to further replicate.
Cool, huh?
Modularity. Just like the binary code used to detail every action of this laptop on which I’m writing, or that laptop, desktop, tablet, or phone on which you’re reading this, so too is a sizable portion of our hereditary information encoded into our genome. Granted, it’s not the end-all-be-all of our extraordinarily adaptable multitudinous phenotypes; life would be far less complex were it otherwise. But it is a foundational element to our cellular gestalt, without which life would be unrecognizable.
